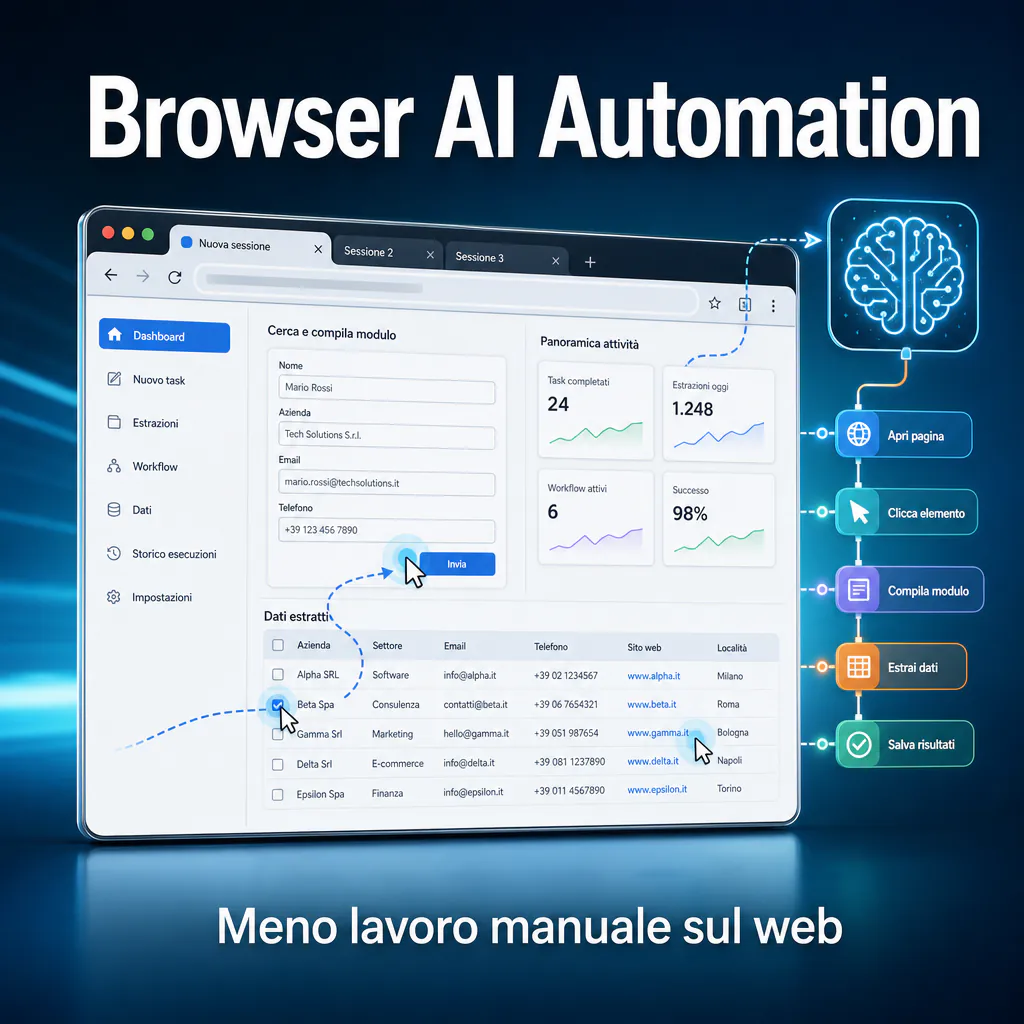
La browser AI automation permet d’automatiser des activités qui nécessitent aujourd’hui des clics, des copier-coller, des contrôles manuels et des étapes répétitives au sein de sites, de logiciels de gestion et de tableaux de bord en ligne. C’est un sujet proche de celui des outils browser AI, mais avec une approche plus opérationnelle : il ne s’agit pas seulement de mieux naviguer, mais de transformer le navigateur en un point d’exécution pour des processus métier, la collecte de données, le remplissage de formulaires et des vérifications récurrentes.
Pour une entreprise B2B, l’enjeu n’est pas d’avoir un agent IA qui clique à la place de l’équipe de manière spectaculaire. L’enjeu est de comprendre quelles activités web peuvent être accélérées, lesquelles doivent être automatisées via API et lesquelles nécessitent un contrôle humain. Cette distinction est fondamentale, car le navigateur est puissant, mais aussi fragile : les interfaces changent, les sessions expirent, des pop-ups, des captchas et des limites anti-bot apparaissent.
Dans cet article, nous voyons ce que signifie réellement l’automatisation browser AI, quels outils sont les plus utilisés, où interviennent Playwright, Puppeteer, Stagehand, Browserbase, MCP et les agents IA, et comment concevoir des workflows fiables sans exposer d’identifiants, de données sensibles ou de processus critiques.
Browser AI automation : ce que cela signifie réellement
Par browser AI automation, on entend l’utilisation d’outils logiciels et de modèles d’intelligence artificielle pour contrôler un navigateur, lire des pages web, interagir avec des formulaires, cliquer sur des boutons, extraire des données et compléter des séquences opérationnelles.
La partie « browser automation » n’est pas nouvelle. Des bibliothèques comme Playwright, Puppeteer et Selenium existent depuis des années et sont utilisées pour les tests, le scraping, la surveillance et les automatisations web. La nouveauté est l’intégration avec des modèles d’IA capables d’interpréter des captures d’écran, du texte, des structures HTML ou des instructions en langage naturel.
En pratique, au lieu d’écrire uniquement du code rigide comme « clique sur le bouton avec ce sélecteur », on peut aujourd’hui créer des systèmes plus flexibles, capables de comprendre qu’un bouton « Envoyer », « Confirmer » ou « Enregistrer les modifications » a une fonction similaire même si sa position ou son texte change légèrement.
Différence entre macros, scripts et agents browser
Toutes les automatisations dans le navigateur ne se valent pas. Il convient de distinguer trois niveaux :
- Macros et automatisations simples : répètent une séquence précise d’actions, comme ouvrir une page, remplir deux champs et télécharger un fichier.
- Scripts de browser automation : utilisent des outils comme Playwright ou Puppeteer pour contrôler le navigateur de manière programmée, avec des logiques, des contrôles, des attentes et une gestion des erreurs.
- Agents browser AI : combinent navigateur, modèle de langage, mémoire de la tâche et capacités décisionnelles pour accomplir des activités moins prévisibles.
Les macros sont faciles à lancer, mais se cassent dès que quelque chose change. Les scripts sont plus stables, mais nécessitent du développement. Les agents browser sont plus flexibles, mais doivent être conçus avec des limites claires, car ils peuvent prendre de mauvaises décisions si la page est ambiguë ou contient des instructions malveillantes.
Ce que l’on peut automatiser sur les pages web, formulaires et tableaux de bord
La browser automation avec IA est utile surtout lorsqu’un processus passe par des interfaces web où il n’existe pas d’intégration directe. Quelques exemples pratiques :
- vérifier chaque matin l’état des commandes, tickets ou dossiers sur des portails externes ;
- télécharger des rapports depuis des tableaux de bord qui n’offrent pas d’API simples ;
- remplir des formulaires répétitifs à partir de données déjà validées ;
- lire des pages produits ou des fiches clients et les transformer en données structurées ;
- surveiller les prix, la disponibilité, les erreurs ou les changements sur des pages publiques ;
- effectuer des contrôles QA sur des sites WordPress, WooCommerce ou des landing pages.
La valeur ne réside pas dans le clic unique économisé, mais dans la continuité du processus. Si une opération prend 20 minutes par jour et implique toujours les mêmes étapes, elle peut devenir un bon candidat pour l’automatisation. Si, en revanche, elle nécessite un jugement commercial, la gestion d’exceptions et des approbations délicates, l’IA doit assister, et non décider seule.
Browser AI automation pour les processus métier B2B
La browser AI automation a du sens lorsqu’elle est liée à un résultat opérationnel clair : moins de temps perdu, moins d’erreurs manuelles, des données plus à jour, des processus plus traçables. Dans le domaine B2B, cela concerne surtout l’administration, les ventes, l’e-commerce, le service client, les opérations marketing et le contrôle qualité.
Le navigateur reste souvent le point le plus « sale » des processus numériques. Les entreprises utilisent des CRM, ERP, portails fournisseurs, marketplaces, outils publicitaires, logiciels de gestion verticaux, bases de données et plateformes SaaS qui ne communiquent pas toujours bien entre eux. Lorsqu’une API manque ou que l’intégration est trop coûteuse, le navigateur devient le seul point d’accès.
Saisie de données, contrôles récurrents et rapports en ligne
Les activités les plus adaptées sont celles qui sont répétitives, basées sur des règles et avec des entrées claires. Par exemple, une équipe peut automatiser la récupération de rapports depuis des plateformes publicitaires, la mise à jour de données dans un logiciel de gestion ou le contrôle d’anomalies sur les commandes et expéditions.
Dans ces cas, l’IA ne doit pas inventer le processus. Elle doit suivre une procédure définie, lire les éléments de la page, reconnaître d’éventuelles variations et signaler quand quelque chose ne correspond pas. Un bon système ne force pas la complétion à tout prix : il s’arrête lorsqu’il rencontre une donnée manquante, une page différente de prévu ou une action risquée.
Cette logique est très différente de l’idée d’un agent complètement autonome. Dans la plupart des projets d’entreprise, la meilleure approche est un workflow guidé : automatisation là où le processus est standard, intervention humaine là où la responsabilité est nécessaire.
Browser AI pour les processus métier sans intégrations natives
Un browser AI pour processus métier devient utile quand le logiciel à contrôler n’offre pas d’API, d’exportations pratiques ou de webhooks. Cela arrive souvent avec des logiciels de gestion datés, des portails de secteur, des espaces réservés, des back-offices de fournisseurs ou des outils verticaux peu flexibles.
Dans ces cas, l’automatisation peut agir comme un pont temporaire. Par exemple : entrer dans le portail, télécharger un CSV, normaliser les données, les envoyer vers Google Sheets, Notion, Airtable, un CRM ou un scénario Make.com. Ensuite, un système d’automatisation plus stable peut poursuivre le travail via API.
C’est là que des entités comme Astra-Pilot peuvent créer de la valeur concrète : non pas en vendant de l’IA générique, mais en concevant des flux mixtes où browser automation, Make.com, API, webhooks et contrôle humain sont combinés de manière pragmatique.
Automatisation browser AI : outils et architectures possibles
Pour construire une bonne automatisation browser AI, il faut choisir l’outil approprié en fonction du processus. Il n’existe pas de solution unique. Un contrôle technique sur une page publique nécessite des outils différents d’un workflow avec connexion, données sensibles et approbations.
Les outils les plus cités aujourd’hui se répartissent en quelques familles : bibliothèques d’automatisation, frameworks IA pour navigateur, navigateurs distants gérés, agents via MCP et solutions RPA plus traditionnelles.
Browser automation avec IA : Playwright, Puppeteer et agents intelligents
Playwright est l’un des outils les plus solides pour contrôler des navigateurs modernes comme Chromium, Firefox et WebKit. Il est souvent utilisé pour les tests de bout en bout, le scraping contrôlé et les automatisations robustes. La documentation officielle souligne l’utilisation des locators, qui aident à identifier les éléments de la page avec des mécanismes d’attente et de retry plus fiables que des sélecteurs fragiles.
Puppeteer, né dans l’écosystème Chrome, reste très utilisé quand le focus est Chromium et le contrôle via DevTools Protocol. Selenium est encore répandu dans les contextes enterprise, surtout là où existent des suites de tests et des infrastructures déjà en place.
La partie IA peut s’ajouter au-dessus de ces outils. Par exemple, un modèle peut décider quel champ remplir, interpréter une erreur, lire un tableau non structuré ou choisir l’étape suivante. Mais la partie exécutive devrait rester le plus possible déterministe : clics, attentes, contrôles, fallback et logging doivent être bien conçus.
En d’autres termes, l’IA est utile pour interpréter et s’adapter. Le code reste fondamental pour rendre le processus répétable.
AI browser automation GitHub : quoi évaluer avant d’utiliser un projet open source
En cherchant ai browser automation GitHub, on trouve de nombreux projets open source basés sur Playwright, Puppeteer, browser-use, MCP server, agents visuels et outils de computer use. Certains sont excellents pour des prototypes, d’autres sont plus expérimentaux.
Avant de les adopter dans un processus métier, il convient d’évaluer certains aspects :
- fréquence des mises à jour et qualité de la documentation ;
- gestion des sessions, cookies, connexions et secrets ;
- support de navigateurs locaux ou distants ;
- possibilité de limiter les actions de l’agent ;
- logging des activités effectuées ;
- gestion des erreurs et des retries ;
- licence et compatibilité avec un usage commercial ;
- dépendances externes et risque de supply chain.
Un dépôt avec beaucoup d’étoiles ne suffit pas. Pour une entreprise, la bonne question est : cet outil peut-il être contrôlé, surveillé et sécurisé ? Si la réponse est incertaine, il ne doit être utilisé qu’en environnement de test ou pour des activités à bas risque.
Dans le paysage actuel, des frameworks comme Stagehand de Browserbase se développent, pensés pour unir l’automatisation Playwright et des instructions IA plus lisibles. Ils sont intéressants car ils cherchent à réduire la fragilité des sélecteurs, mais n’éliminent pas la nécessité de bien concevoir la sécurité, les permissions et les fallbacks.
Quand automatiser des pages web avec l’IA et quand utiliser des API
Une règle pratique : s’il existe une API stable, documentée et accessible, il est presque toujours préférable de l’utiliser. Automatiser un navigateur doit être un choix conscient, pas le premier raccourci.
Les API sont plus rapides, plus traçables et moins sensibles aux changements graphiques. Le navigateur, en revanche, simule le comportement d’un utilisateur et dépend donc d’interfaces, de sessions, de cookies, de modales, de chargements JavaScript et de contrôles anti-automatisation.
API, webhooks et intégrations Make.com : le choix le plus stable
Pour des processus métier répétables, les API et webhooks sont la base la plus solide. Si un CRM, un e-commerce ou un logiciel de gestion permet de lire et d’écrire des données via API, il est préférable de construire une intégration directe. Make.com, n8n, Zapier ou des intégrations custom peuvent gérer les triggers, transformations, notifications et mises à jour avec une plus grande fiabilité.
Par exemple, s’il faut synchroniser de nouvelles commandes WooCommerce avec un logiciel de gestion, utiliser l’API de WooCommerce est beaucoup plus stable que d’ouvrir le navigateur, d’entrer dans le panneau admin et de copier les données de commande. S’il faut mettre à jour un lead dans HubSpot, Salesforce ou Airtable, l’API évite les erreurs visuelles et réduit les temps.
La browser automation intervient quand un meilleur canal manque. Elle ne devrait pas remplacer des intégrations saines là où elles existent déjà.
Automatiser des pages web avec l’IA quand il n’existe pas d’API pratiques
Automatiser des pages web avec l’IA devient pertinent quand le seul accès disponible est l’interface web. C’est fréquent dans les portails publics, les logiciels de gestion legacy, les marketplaces fermées, les espaces clients de fournisseurs ou les logiciels verticaux sans API modernes.
Dans ces cas, l’IA peut aider à reconnaître les contenus et les variations de la page. Par exemple, elle peut lire un message d’erreur, comprendre qu’un tableau a changé d’ordre, extraire des données d’un écran ou gérer une étape non identique à la veille.
La conception doit cependant être réaliste. Un workflow fiable devrait prévoir :
- des entrées structurées et validées avant l’exécution ;
- des actions autorisées et des actions interdites ;
- des contrôles avant d’envoyer des données ou de confirmer des opérations ;
- un log des pages visitées et des modifications effectuées ;
- une notification humaine quand le système rencontre un nouveau cas ;
- un environnement séparé pour les tests et la production.
Cette approche permet d’exploiter l’IA sans transformer chaque automatisation en un risque opérationnel.
Risques techniques : connexions, scraping, captcha et données sensibles
La browser AI automation ne doit pas être traitée comme un simple script inoffensif. Lorsqu’un système contrôle un navigateur, il peut accéder à des données, des sessions, des comptes et des fonctions opérationnelles. Cela change le profil de risque.
Le problème n’est pas seulement technique. Il est aussi légal, organisationnel et sécuritaire. Une automatisation qui lit des données publiques a un risque. Un agent qui entre dans un compte administrateur, télécharge des données clients ou confirme des commandes en a un autre.
Sessions web, identifiants et gestion sécurisée des accès
Les identifiants ne devraient jamais être insérés dans des prompts, des fichiers non protégés ou des configurations improvisées. Un système sérieux utilise des secret managers, des permissions limitées, des comptes dédiés et des logs accessibles.
Pour les processus métier, il est conseillé de créer des utilisateurs séparés pour les automatisations, avec des privilèges minimaux. Si le workflow doit seulement lire des rapports, il ne doit pas avoir de permissions de modification. S’il doit remplir des brouillons, il ne doit pas pouvoir envoyer ou publier sans approbation.
Autre point délicat : les sessions persistantes. Beaucoup d’outils permettent de réutiliser des cookies ou des profils de navigateur déjà authentifiés. C’est pratique, mais doit être géré avec attention. Si un agent travaille dans une session avec un accès complet aux emails, CRM, comptes publicitaires ou panneaux admin, une erreur peut avoir des conséquences réelles.
Les outils de computer use et d’agentic browsing les plus modernes introduisent des atténuations comme des confirmations humaines, des blocages sur actions sensibles et des politiques de sécurité. Ils sont utiles, mais ne remplacent pas une bonne architecture des permissions.
Limites anti-bot, captcha, ToS et continuité opérationnelle
Les captchas, rate limits, blocages anti-bot et contrôles sur les empreintes de navigateur ne sont pas des détails marginaux. Ce sont des signaux que la plateforme veut limiter ou vérifier l’automatisation. Les contourner peut violer les conditions de service ou créer des problèmes légaux.
C’est pourquoi il est important de distinguer l’automatisation légitime de ses propres processus et le scraping agressif de services tiers. Surveiller son propre site, tester une landing page ou télécharger des rapports depuis un compte entreprise est différent de la collecte de données de masse depuis des plateformes qui l’interdisent.
Un autre risque récent concerne la prompt injection. Les agents browser lisent des contenus web et peuvent recevoir des instructions cachées dans des pages, commentaires, emails ou documents. Si un agent peut aussi accomplir des actions, une page malveillante pourrait tenter d’influencer son comportement. C’est pourquoi il convient de limiter les actions disponibles, de séparer la lecture de l’écriture, et de demander une approbation humaine pour les opérations sensibles.
La continuité opérationnelle nécessite aussi une surveillance. Une automatisation qui fonctionne aujourd’hui peut se casser demain parce qu’une plateforme change de layout, introduit un pop-up ou modifie le nom d’un champ. Chaque workflow important doit avoir des alertes, des tests périodiques et un moyen clair de comprendre où il s’est bloqué.
Comment concevoir un workflow browser AI fiable
Un bon projet de browser automation avec IA part du processus, pas de l’outil. On mappe d’abord le travail manuel, puis on décide quelles étapes automatiser, lesquelles intégrer via API et lesquelles laisser à l’opérateur.
Une carte utile inclut : entrées, systèmes impliqués, identifiants nécessaires, données traitées, fréquence, exceptions connues, actions irréversibles et critères de succès. Ce n’est qu’après qu’il a du sens de choisir entre script Playwright, framework IA, Make.com, API ou agent browser avancé.
Automatisations simples, workflows assistés et agents browser avancés
Il y a trois modèles de conception à considérer.
Automatisations simples : idéales pour des tâches stables et répétitives. Par exemple : ouvrir une page, vérifier une valeur, télécharger un fichier, envoyer une notification. Ici, l’IA ne sert souvent à rien, ou sert seulement à interpréter un texte.
Workflows assistés : adaptés quand l’automatisation prépare le travail et l’utilisateur approuve. Par exemple : collecter des données de plusieurs sources, remplir un brouillon dans un logiciel de gestion, créer un résumé et demander confirmation avant l’envoi.
Agents browser avancés : utiles quand le parcours n’est pas toujours identique. Par exemple : naviguer sur plusieurs pages, interpréter des messages, chercher des informations, comparer des résultats et décider de l’étape suivante. Ils sont puissants, mais nécessitent des limites, des sandboxes, des logs et des approbations.
Ceux qui évaluent des outils comme les browser avec IA devraient partir de cette question : a-t-on vraiment besoin d’un agent autonome ou un workflow assisté bien conçu suffit-il ? Dans la plupart des cas d’entreprise, la seconde option est plus sûre et produit des résultats plus rapidement.
Surveillance, fallback et intégration avec les processus Astra-Pilot
Un workflow fiable n’est pas seulement un bot qui fonctionne. C’est un système que l’on peut contrôler. Il doit avoir des logs, des captures d’écran d’erreur, des notifications, des retries raisonnables et un fallback humain.
Par exemple, si une automatisation entre dans un portail fournisseur et ne trouve pas le bouton prévu, elle ne doit pas cliquer au hasard. Elle doit s’arrêter, sauvegarder l’état, notifier l’équipe et peut-être ouvrir une tâche avec un contexte suffisant : URL, screenshot, erreur, dernière étape complétée.
C’est là que l’automatisation browser se connecte bien à des outils comme Make.com. Le navigateur peut récupérer ou insérer des données là où il n’y a pas d’API. Make.com peut orchestrer le reste : mettre à jour des feuilles, CRM, emails, Slack, bases de données, rapports et notifications. Les API peuvent gérer les systèmes les plus stables. L’IA peut interpréter des textes, classer des cas et assister les opérateurs.
Dans une logique Astra-Pilot, le projet idéal n’est pas de mettre de l’IA partout, mais de réduire le travail manuel là où il pèse vraiment. Un bon flux peut partir d’un audit du processus, passer par une preuve contrôlée sur quelques cas et arriver seulement après à une mise en production avec surveillance.
Pour choisir les outils, il peut être utile de comparer différentes solutions. Les meilleurs AI browser sont intéressants pour des activités personnelles, la recherche et l’assistance à la navigation. Pour des processus métier répétables, cependant, des architectures plus solides sont souvent nécessaires : Playwright, API, Make.com, bases de données, permissions séparées et un système de contrôle.
Sources techniques consultées
Pour maintenir l’article à jour, des sources techniques et documentations officielles sur la browser automation, les agents browser et la sécurité ont été consultées. Parmi celles-ci : la documentation Playwright sur les locators et mécanismes d’auto-waiting, le dépôt officiel Microsoft Playwright MCP, la page officielle Browserbase Stagehand et le guide OpenAI sur le computer use.
Erreurs communes à éviter dans les projets de browser AI automation
Beaucoup de projets échouent parce qu’ils partent de l’outil plutôt que du processus. On installe un agent, on essaie une démo, on obtient un résultat intéressant et on pense pouvoir le mettre tout de suite en production. En réalité, un environnement d’entreprise demande plus de discipline.
Automatiser des processus pas encore clairs
Si une activité manuelle change à chaque fois, l’automatisation ne la rendra pas magiquement ordonnée. Il faut d’abord standardiser le processus. Qui fait quoi ? Quelles données sont nécessaires ? Quelles exceptions sont acceptables ? Quand faut-il s’arrêter ?
C’est seulement après qu’il a du sens d’automatiser. Sinon, on risque de créer un agent qui reproduit la confusion, les erreurs et les étapes inutiles.
Utiliser l’IA là où une règle simple suffit
L’IA est utile quand elle doit interpréter, classer ou s’adapter. Elle ne sert pas à cliquer toujours sur le même bouton ou à lire toujours la même cellule d’un tableau. Dans ces cas, le code traditionnel et les API sont moins chers, plus rapides et plus contrôlables.
Une bonne architecture utilise l’IA seulement aux points où elle ajoute de la valeur. Le reste doit rester simple.
Oublier le contrôle humain sur les actions sensibles
Envoyer des emails, modifier des données clients, confirmer des commandes, publier des contenus, télécharger des données personnelles ou changer des paramètres de compte sont des actions sensibles. Elles ne devraient pas être laissées à un agent sans contrôles.
Le meilleur modèle est souvent « human in the loop » : l’automatisation prépare, l’être humain approuve, le système exécute et enregistre.
Cas d’usage concrets pour entreprises, marketing et e-commerce
La browser AI automation est particulièrement intéressante quand elle touche des activités opérationnelles qui pompent du temps chaque semaine. Pas besoin de chercher des cas futuristes. Les meilleures économies viennent souvent de processus ennuyeux et fréquents.
Lead generation et enrichissement de données
Un système peut visiter des sites d’entreprises, lire des pages de contact, vérifier les technologies utilisées, collecter des signaux publics et préparer une fiche lead. S’il est connecté à un CRM ou à une feuille de travail, il peut aider l’équipe commerciale à se concentrer sur les prospects les plus prometteurs.
Ici, il faut respecter la vie privée, les conditions des sites et les limites de collecte. L’objectif n’est pas de scraper des données de manière indiscriminée, mais de réduire le travail manuel sur des informations légitimement accessibles et utiles à la qualification commerciale.
Contrôle qualité sur sites WordPress et WooCommerce
Pour un site WordPress ou WooCommerce, le navigateur peut effectuer des contrôles récurrents : ouverture de pages clés, vérification de formulaires, test du checkout, contrôle d’erreurs visuelles, présence d’éléments SEO, temps de réponse perçus et problèmes après mises à jour.
Ce type d’automatisation est très utile car il simule le comportement réel d’un utilisateur. Une API peut dire que le site répond. Un navigateur peut voir si le formulaire n’envoie pas, si le panier a une erreur ou si une bannière couvre le bouton d’achat.
Back-office, rapports et portails externes
Beaucoup d’entreprises passent des heures à télécharger des rapports de différentes plateformes, renommer des fichiers, les charger dans des dossiers partagés et mettre à jour des feuilles. Une partie de ce travail peut être automatisée avec navigateur, IA et intégrations.
Par exemple, le navigateur télécharge le rapport d’un portail sans API, Make.com l’archive, un parser le normalise et un modèle IA génère un résumé pour l’équipe. Le résultat n’est pas seulement du temps économisé : c’est aussi une plus grande ponctualité des données.
Comment évaluer si un processus est adapté à la browser AI automation
Avant de développer une automatisation, il convient d’attribuer un score au processus. Pas besoin d’un modèle complexe. Quelques questions pratiques suffisent.
| Critère | Question à poser | Signal positif |
|---|---|---|
| Fréquence | À quelle fréquence l’activité est-elle effectuée ? | Chaque jour ou plusieurs fois par semaine |
| Répétabilité | Les étapes sont-elles presque toujours les mêmes ? | Séquence claire et documentable |
| Valeur | Combien de temps ou de risque réduit-elle ? | Économie mesurable ou moins d’erreurs critiques |
| Accès | Existe-t-il une API ? | Non, ou API incomplète |
| Risque | Gère-t-elle des données sensibles ou des actions irréversibles ? | Risque bas ou approbation humaine possible |
Si un processus est fréquent, répétable, coûteux et sans API pratiques, c’est un bon candidat. Si, en revanche, il est rare, ambigu et plein de décisions délicates, mieux vaut partir d’un assistant qui prépare les informations, pas d’un agent qui agit en autonomie.
Quand partir avec un prototype
Un prototype a du sens quand on peut tester sur des données limitées, des comptes non critiques et des cas contrôlés. L’objectif n’est pas de démontrer que l’IA peut le faire, mais de mesurer la stabilité du flux.
Un bon test devrait vérifier les temps d’exécution, les erreurs, les cas limites, la gestion des connexions, l’impact sur les utilisateurs réels et la qualité des données produites.
Quand éviter l’automatisation browser
Mieux vaut éviter la browser automation quand le service interdit clairement l’automatisation, quand des données hautement sensibles sont impliquées sans mesures de sécurité adéquates, quand l’interface change souvent ou quand une API officielle résout déjà le problème de manière plus propre.
Il faut aussi l’éviter quand le processus n’a pas été validé. Automatiser une activité inutile signifie seulement la faire plus rapidement.
Le rôle des agents browser avancés
Les agents browser avancés représentent la partie la plus intéressante et la plus délicate du secteur. Ils peuvent lire un écran, raisonner sur un objectif, choisir des actions et compléter des tâches multi-étapes. Cela les rend adaptés à la recherche, au remplissage assisté, à la collecte de données et à la navigation dans des systèmes complexes.
Un browser AI agent peut être utile quand le parcours n’est pas complètement prévisible. Par exemple, chercher des informations dans un portail, comparer plusieurs pages, interpréter des messages et préparer un output structuré.
Pourquoi les agents ne doivent pas avoir de liberté totale
Un agent trop libre est difficile à contrôler. S’il peut visiter n’importe quel site, lire n’importe quelle donnée et accomplir n’importe quelle action, il devient un risque. Dans les projets sérieux, l’agent doit avoir un périmètre : domaines autorisés, actions autorisées, données accessibles, limites de temps, budget et conditions d’arrêt.
C’est encore plus vrai pour les workflows avec des comptes connectés. La commodité d’un agent qui travaille dans des sessions déjà ouvertes doit être équilibrée avec des profils dédiés, des permissions réduites et des approbations.
Pourquoi le futur sera hybride
Le futur de la browser AI automation ne sera pas seulement composé d’agents autonomes. Il sera hybride : API là où c’est possible, automatisations browser là où c’est nécessaire, IA pour interpréter, opérateurs humains pour approuver et systèmes d’orchestration pour tout lier.
C’est aussi la direction la plus concrète pour les entreprises qui veulent réduire le travail manuel sans introduire une complexité ingérable. La technologie est prête pour de nombreux cas d’usage, mais l’avantage compétitif naît de la conception du processus, pas de la démo la plus spectaculaire.